Introduction to Transformers#
Transformers are a type of neural network architecture that has become a cornerstone in Natural Language Processing (NLP) and beyond. They were introduced in the 2017 paper “Attention is All You Need” by Vaswani et al. Transformers are a milestone because of the Attention Mechanism, especially self-attention.
For a short introduction to Transformers and their Self-Attention machanism, click below:
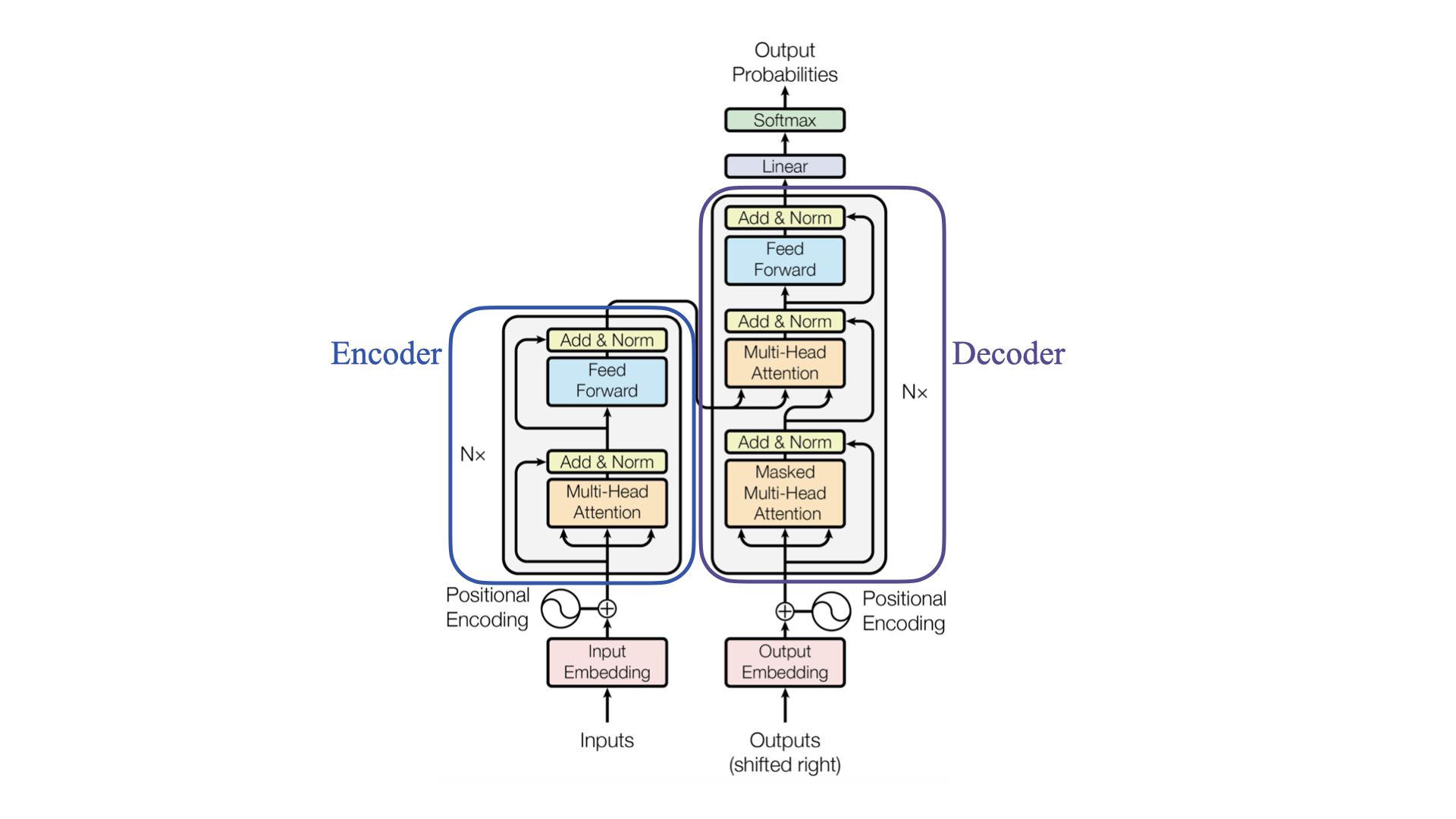
Encoder-Decoder Structure#
The Transformer architecture is divided into two main parts:
1. Encoder: The encoder processes the input data (like a sentence in a translation task) and encodes it into a context-rich representation. It consists of a stack of layers, each containing a self-attention mechanism and a feed-forward neural network.
2. Decoder: The decoder takes the encoded input and generates the output sequence (like a translated sentence). It also consists of a stack of layers, each with two attention mechanisms (one that attends to the output of the encoder and one that is a masked self-attention mechanism to prevent the decoder from seeing future tokens in the output sequence) and a feed-forward neural network.
The Self-Attention Mechanism#
Before digging into the encoder and decoder architecture, let’s talk about THE most important concept of transformers: the self-attention mechanism.
The goal of self-attention is to generate a representation of each element in a sequence by considering the entire sequence. For example, in a sentence, the representation of a word is computed by attending to all words in the sentence, including the word itself. Here, the word “attending” refers to the process where the model determines how much focus or importance to assign to each element in the input sequence when computing a representation for a specific element.
Components
The main components are the tree vectors Queries (Q), Keys (K), and Values (V), which are computed for each element in the input sequence. These are typically created by multiplying the input embeddings with three different weight matrices.

Q represents the current element in the sequence, used to compute attention scores against all keys. K Represents all elements in the sequence. The attention scores are calculated by the dot product of the query with each key, determining the level of attention each element receives. V is the actual representation of the sequence elements. The attention mechanism uses the computed scores to create a weighted sum of these values, forming the output for each element.
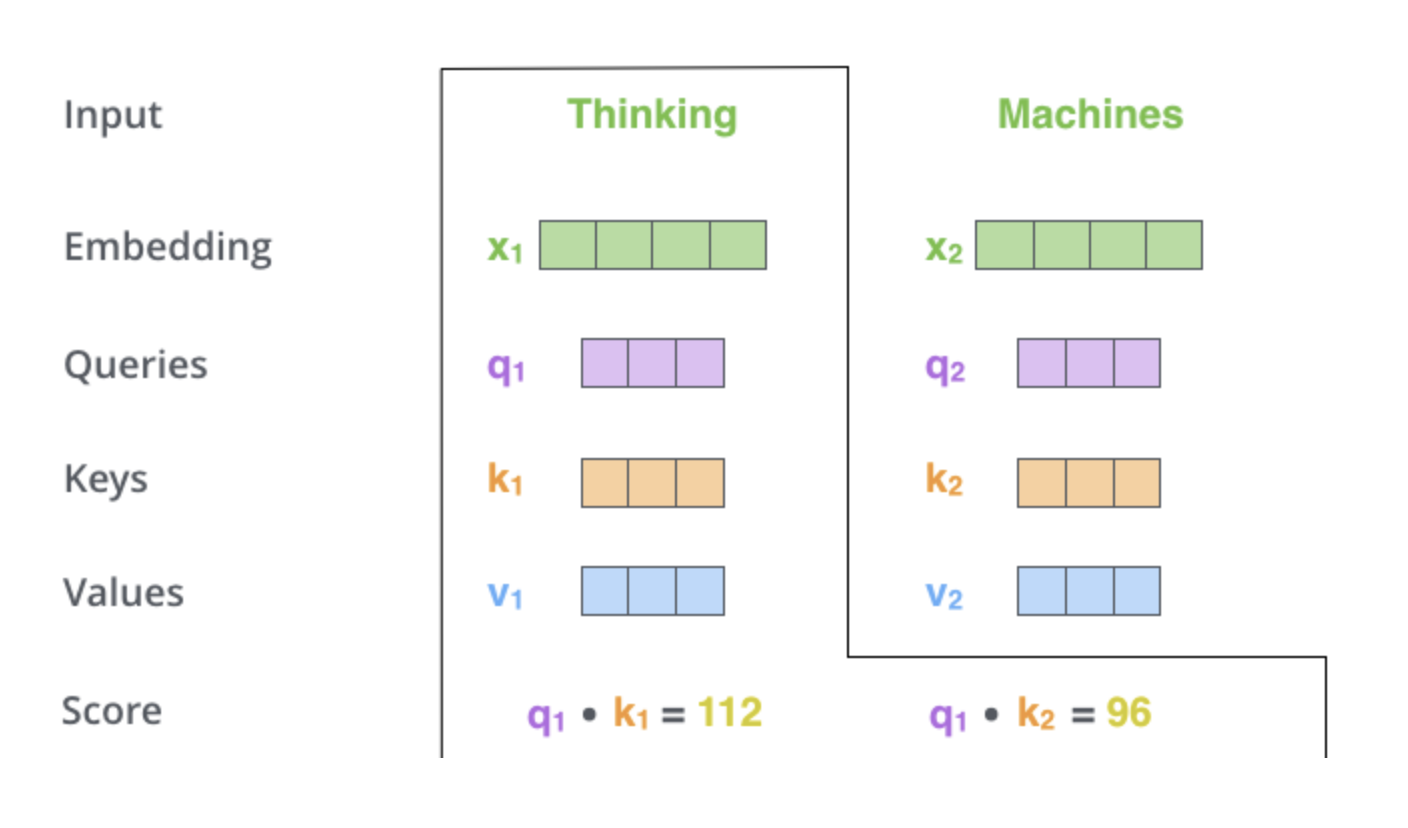
Attention Scores
The model calculates the attention score for each pair of elements in the sequence. This is typically done by taking the dot product of the query vector of one element with the key vector of another, which indicates how much focus to put on other parts of the input sequence when encoding a particular element.
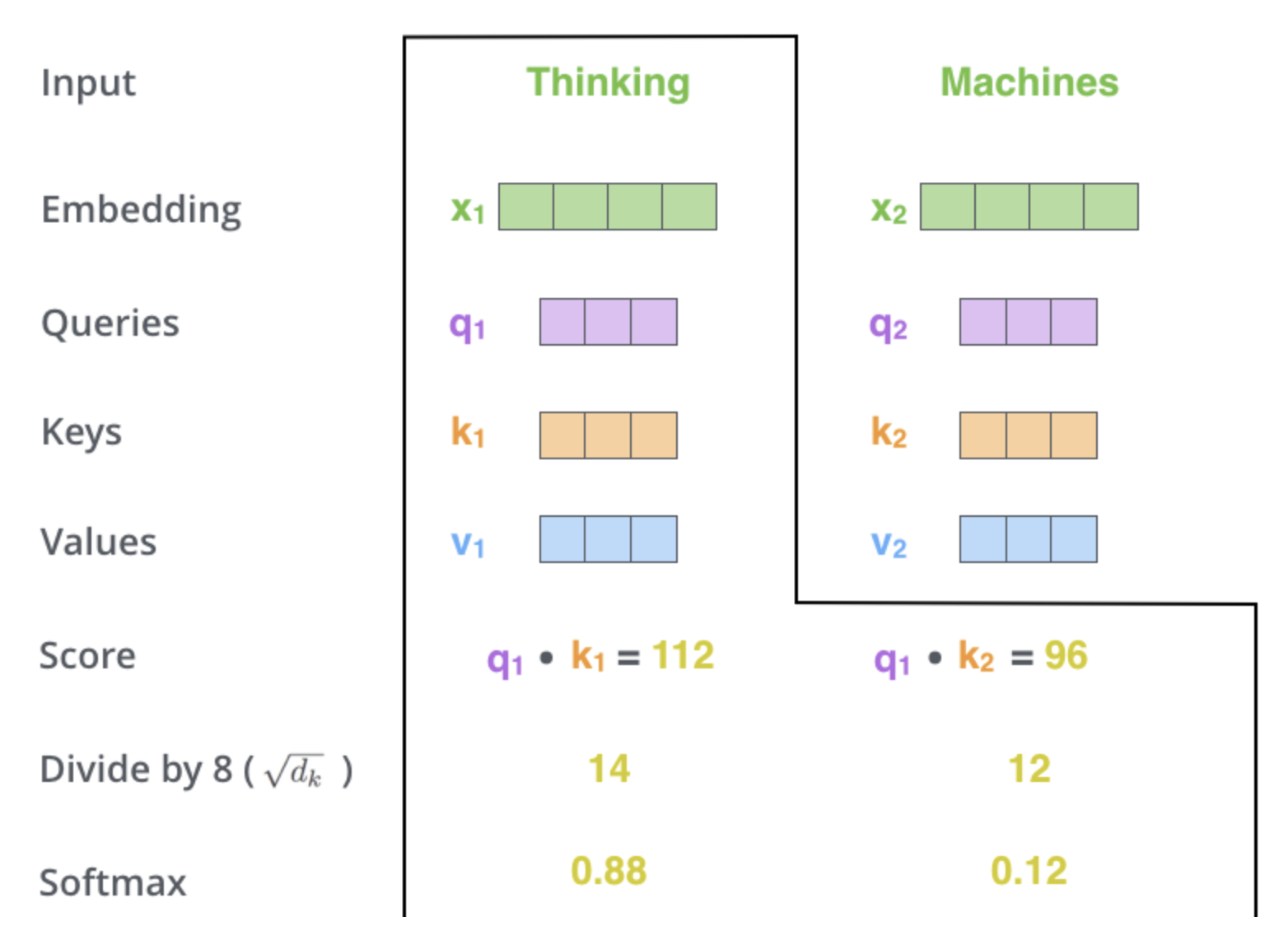
Scaling and Normalization
The dot product scores are scaled down (usually by the square root of the dimension of the key vectors), and a softmax function is applied to obtain the final attention weights. This normalization ensures that the weights across the sequence sum up to 1.
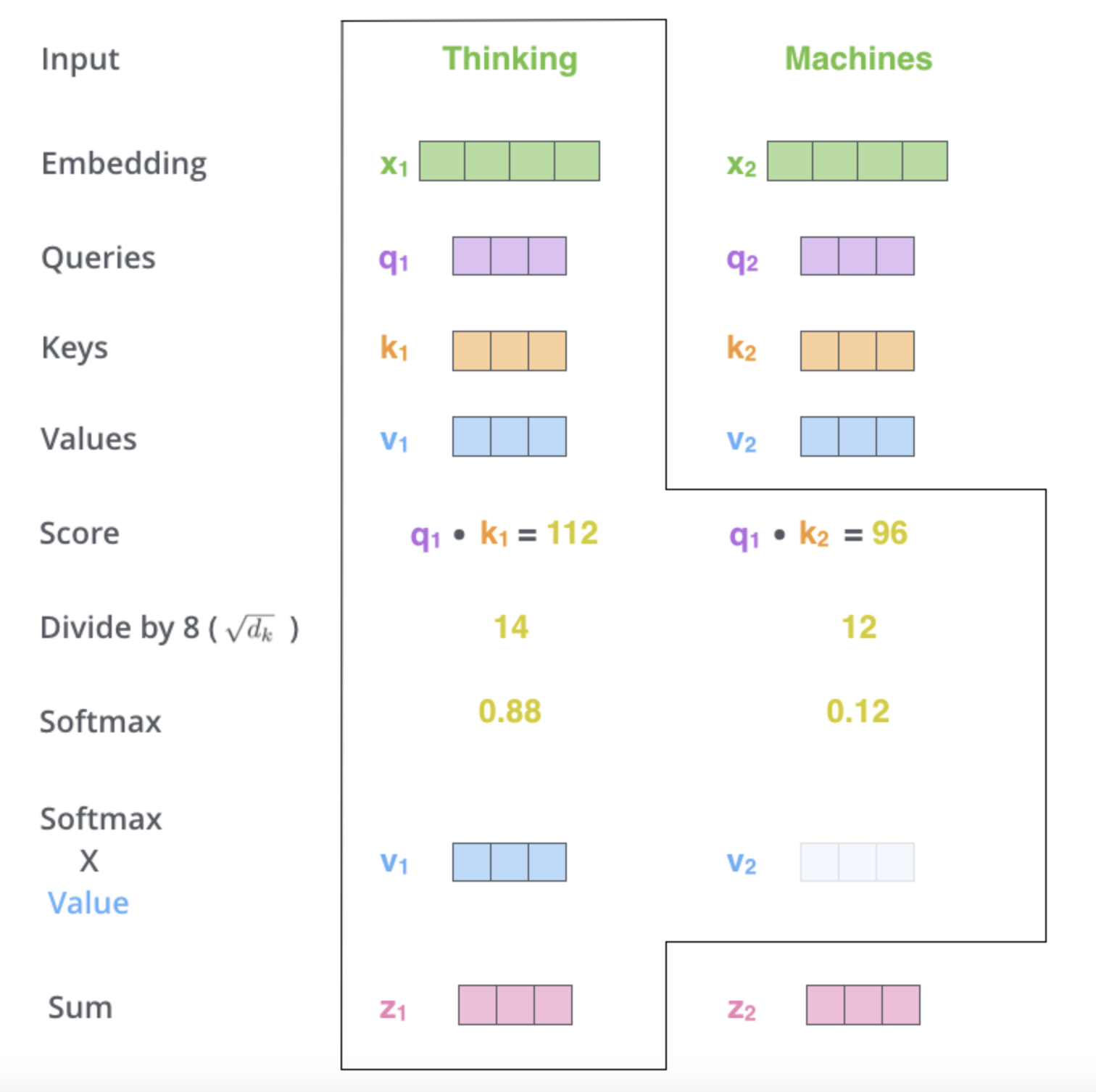
Weighted Sum
The output for each element is then a weighted sum of the value vectors, where the weights are the attention scores. This results in a new representation for each element incorporating information from the entire sequence.
The overall mechanism, i.e. the sacled dot-product attention, can be summarized in the figure below.

The Mechanism of Multi-Head Attention#
In multi-head attention, the attention mechanism is run in parallel multiple times. Each parallel run is known as a “head.” Each head learns to pay attention to different parts of the input, allowing the model to capture various aspects of the information (like different types of syntactic or semantic relationships).
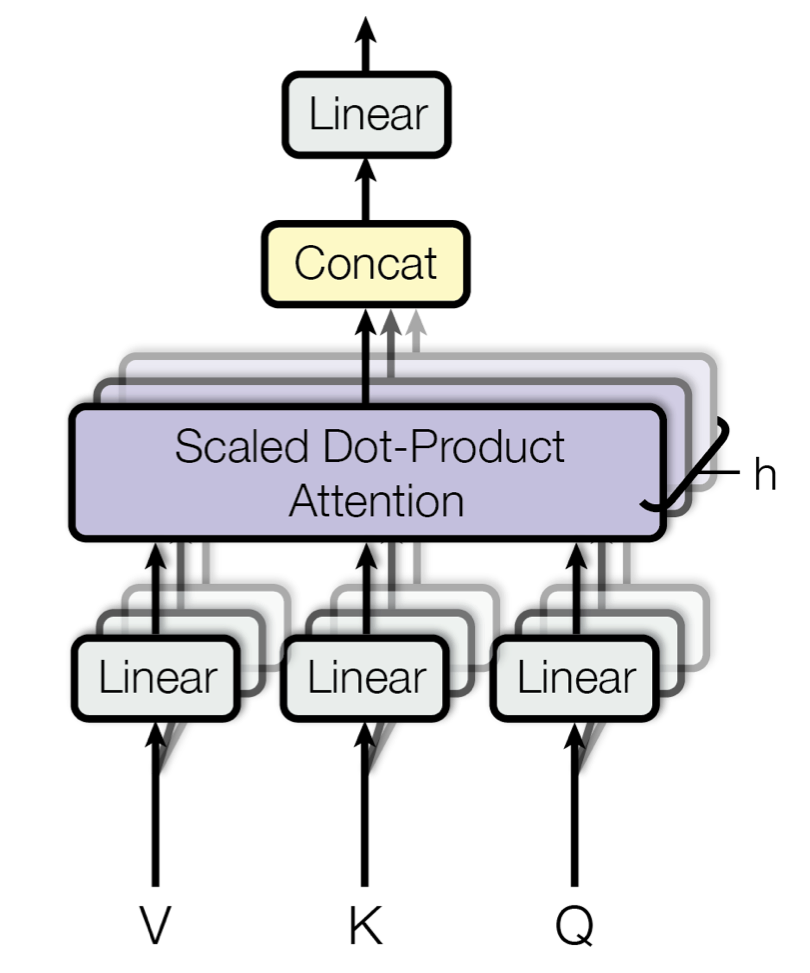
The outputs of all attention heads are concatenated and then linearly transformed into the final output. This combination allows the model to pay attention to information from different representation subspaces at different positions.

Vision Transformers#
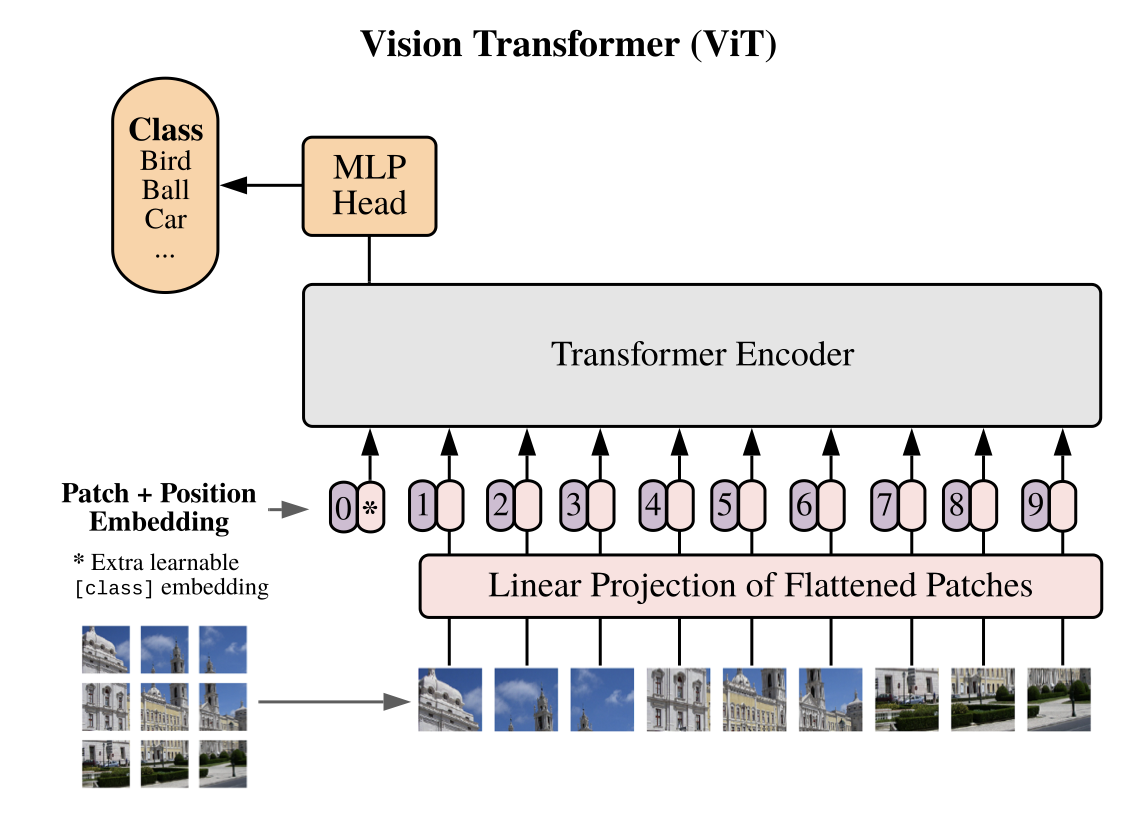
The Vision Transformer (ViT) adapts the principles of the Transformer architecture, originally designed for natural language processing tasks, to image data. Unlike traditional convolutional neural networks (CNNs) that use convolutional layers to process image pixels, a Vision Transformer splits an image into fixed-size patches, treats each patch as a “token” similar to a word in a sentence, and then processes these patches using the self-attention mechanisms. ViT utilizes only the encoder part of the traditional transformer architecture. Unlike the original transformer model, which was designed for sequence-to-sequence tasks like machine translation and thus included both an encoder and a decoder, ViT is adapted for classification tasks and therefore does not require a decoder.
Representation of an Image as a Sequence:
To transform the image into a sequence, the image is first Patch Embedded by dividing it into small, non-overlapping patches, typically of size 16×1616×16 pixels. Each patch is flattened into a vector, and then a linear projection is applied to embed these patches into a high-dimensional space. In a second step the Position Embedding is added to the Patch Embedding. Since Transformers do not inherently capture positional information (unlike CNNs, which process spatial data directly), positional embeddings are added to the patch embeddings to maintain the spatial structure of the image.
Transformer Encoder:
The Vit typically uses a stack of Transformer encoder layers (without the decoder) to process the patch embeddings and generate contextualized representations of the image. It lacks a decoder because it is primarily designed for tasks where the goal is to produce a single output or a classification based on the input image, rather than generating a sequence or reconstructing the input. The encoder part of the ViT, like the traditional transformers consists of the following key components:
Multi-Head Self-Attention: Enables the model to focus on different parts of the image, capturing both local and global information.
Feed-Forward Neural Network: Processes each patch embedding independently to learn complex representations.
Residual Connections and Layer Normalization: Each Multi-Head Self-Attention and Feed-Forward Neural Network sub-layer is followed by residual connections and layer normalization for stable training and effective gradient flow.
Classification Head:
After processing the patches, a classification token (similar to the [CLS] token in BERT) is prepended to the sequence of embedded image patches. This token is initialized randomly and is trained along with the rest of the model. The role of the [CLS] token is to represent the entire imagethrough which the ViT learns to capture the global context of the image during training, which is crucial for classification tasks. The final representation of this token is passed through a classification head to make predictions, such as object classification.
References#
Original Attention paper: Vaswani. Attention is all you need. Advances in neural information processing systems. 2017.
- Blogpost on Transformers:
- Tutorials on Building a Transformer with PyTorch:
Original ViT paper: Kolesnikov, A., Dosovitskiy, A., Weissenborn, D. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR. 2021